全文检索 #
- MySQL存储数据时,采用表格的方式(行和列)的方式来进行存储
- Redis存储数据时,采用K-V结构的方式来进行存储
- 当数据量非常庞大时(T,P级),提升查询效率
需求 #
-
说:Redis简单,知道Key就可以,但如果其他人问你说我不知道Key,我只是知道大概的值,如何提升效率?
-
说:MySQL在某些常用列上,添加索引,使用索引来提升查询效率,问你:没有使用索引的列,如何快速查询?
-
解决方案:
-
- 如果有一种东西,它可以根据全部数据(不分行,列)的所有内容,都建立索引的话,此时,我再根据索引查询,快了吧?
- 全文检索:将数据库的所有数据,都进行分析出关键词,然后针对关键词建立索引
-
- 查询时:就可以根据关键词快速的检索数据出来
场景 #
- 百度,谷歌等一系列的搜索引擎
- 搜索引擎爬我们的网页数据,将网页数据进行分析,分析出关键词,然后针对关键词进行建立索引
ES的概述 #
ElaticSearch,简称为ES, ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器;处理PB级别(大数据时代)的数据。ES也使用Java开发、并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用
ES提供的功能 #
- 分布式的搜索引擎和数据分析引擎
- 搜索:百度,谷歌,搜狗,网站的站内检索(起点……),IT系统的检索
- 数据分析:百度热词排行榜,百度竞价,热点新闻,猜你喜欢……
- 全文检索,结构化查询
- 全文检索:针对所有的数据,提供关键词的检索
- 结构化查询:也可以提供类似于MYSQL中的结构化查询
- 对海量数据进行存储以及实时性的处理
- NOSQL库都有特点:内存处理,天生就适合做集群
ES的适合场景 #
- 维基百科,类似百度百科,全文检索,高亮,搜索推荐(权重,百度)
- The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众 反馈(好,坏,热门,垃圾,鄙视,崇拜)
- Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
- GitHub(开源代码管理),搜索上千亿行代码
- 电商网站,检索商品
- 日志数据分析,logstash采集日志,ES进行复杂的数据分析,ELK技术, elasticsearch+logstash+kibana
- 商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如 说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买。
- BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费 金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
- 国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
ES的特点 #
- 天生支持集群,可以实时处理以PB为单位的数据,中小型公司也可以用
- ES不是什么新技术,它就是对Lucene的封装,将全文检索,数据分析,分布式全部整合到一起了
- 对于程序员来说,它是一种开箱即用的技术,而且你在用它时,不会对现有其他技术造成任何的干扰
- 针对NoSQL库,针对RDBMS的不足,提供了补充机制
ES的常见术语 #
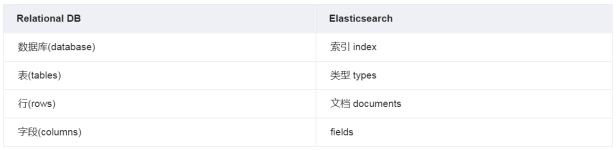
-
索引:就是关系型数据库中的数据库
-
类型:就是关系型数据库中的表
-
文档:就是关系型数据库中表中的一行数据(Document),文档
-
属性:一行数据的列(字段)
Mapping #
相当于MySQL的Schema ,是对表(index)结构的定义,所以,在使用表之前,先对需要的表结构进行定义
Mapping的数据类型 #
| 属性名字 | 说明 |
|---|---|
| text | 用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引 |
| keyword | 关键字,不进行分词 |
| long | 有符号64-bit integer:-2^63 ~ 2^63 - 1 |
| integer | 有符号32-bit integer,-2^31 ~ 2^31 - 1 |
| short | 有符号16-bit integer,-32768 ~ 32767 |
| byte | 有符号8-bit integer,-128 ~ 127 |
| double | 64-bit IEEE 754 浮点数 |
| float | 32-bit IEEE 754 浮点数 |
| half_float | 16-bit IEEE 754 浮点数 |
| boolean | true,false |
| date | 日期类型 |
| binary | 该类型的字段把值当做经过 base64 编码的字符串,默认不存储,且不可搜索 |
类型自动识别 #
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示
| 类型 | 规则 |
|---|---|
| 字符串 | 匹配到日期格式,设置成Date。 字符串为数字时,当成字符串处理,但我们设置转换为数字。 其他情况,类型就是Text,并且会增加keyword的子字段 |
| 布尔值 | Boolean |
| 浮点数 | Float |
| 整数 | Long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型决定 |
| 空值 | 忽略 |
指定表中字段的类型 #
PUT /index_
{
"mappings": {
"properties": {
"key":{
"type": "type_name"
}
}
}
}
相比MySQL的索引的优点(面试题) #
- 可以根据关键词,快速定位凡是包含过该关键词的文档
- 比MySQL灵活,MySQL使用
like %导致索引失效,而ES靠关键词 - ES可以自己完成数据分析,得出关键词出现的频率
- ES所有字段都可以参与索引,而MySQL只有该频率的字段才可以参与索引