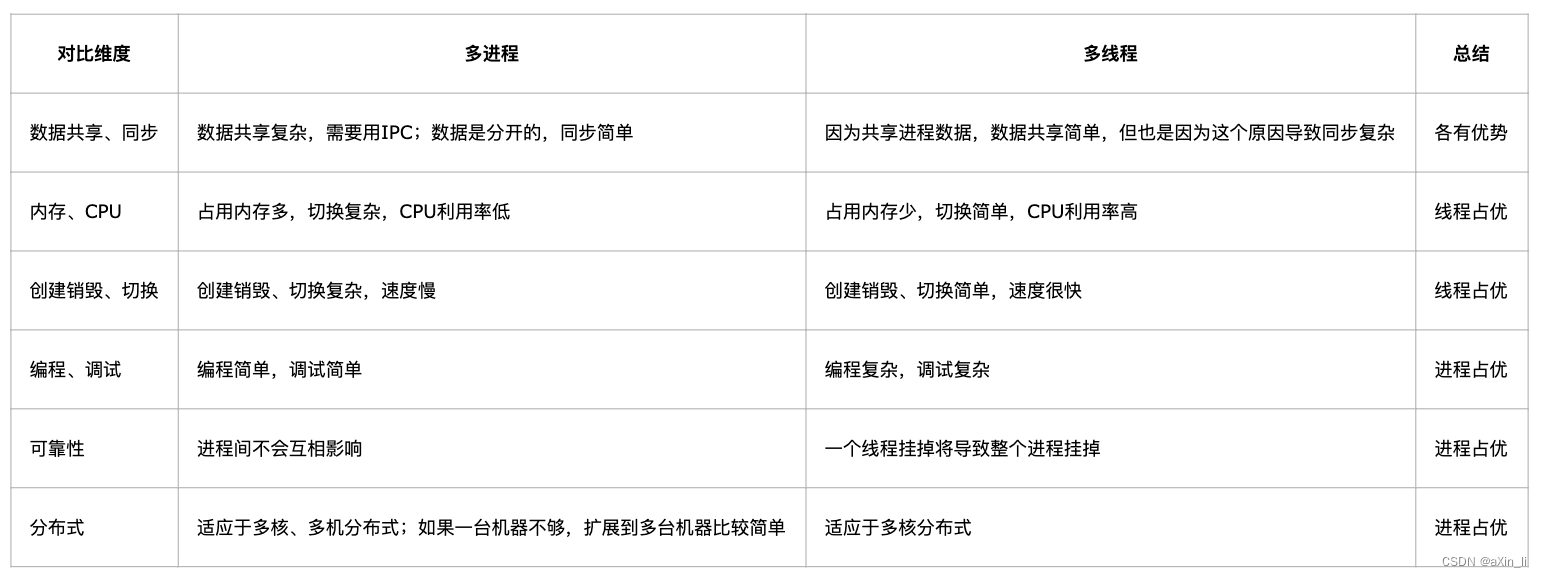
多进程和多线程的选择
node.js 目前有两种方案,一种是使用children_process或者cluster开启多进程进行计算,一种是使用worker_thread 开启多线程进行计算
children_process多进程简介
我们都知道 Node.js 是以单线程的模式运行的,但它使用的是事件驱动来处理并发,这样有助于我们在多核 cpu 的系统上创建多个子进程,从而提高性能。
每个子进程总是带有三个流对象:child.stdin, child.stdout 和child.stderr。他们可能会共享父进程的 stdio 流,或者也可以是独立的被导流的流对象。
Node 提供了 child_process 模块来创建子进程,方法有:
exec:child_process.exec使用子进程执行命令,缓存子进程的输出,并将子进程的输出以回调函数参数的形式返回。spawn:child_process.spawn使用指定的命令行参数创建新进程。fork:child_process.fork是spawn()的特殊形式,用于在子进程中运行的模块,如fork('./son.js')相当于spawn('node', ['./son.js'])。与spawn方法不同的是,fork会在父进程与子进程之间,建立一个通信管道,用于进程之间的通信。
exec方法
child_process.exec 使用子进程执行命令,缓存子进程的输出,并将子进程的输出以回调函数参数的形式返回。
child_process.exec(command[, options], callback)
参数说明如下:
-
command: 字符串, 将要运行的命令,参数使用空格隔开 -
options:对象,可以是:-
cwd,字符串,子进程的当前工作目录 -
env,对象 环境变量键值对 -
encoding,字符串,字符编码(默认:utf8) -
shell,字符串,将要执行命令的 Shell(默认: 在 UNIX 中为/bin/sh, 在 Windows 中为cmd.exe, Shell 应当能识别-c开关在 UNIX 中,或/s /c在 Windows 中。 在Windows 中,命令行解析应当能兼容cmd.exe) -
timeout,数字,超时时间(默认: 0) -
maxBuffer,数字, 在 stdout 或 stderr 中允许存在的最大缓冲(二进制),如果超出那么子进程将会被杀死 (默认: 200*1024) -
killSignal,字符串,结束信号(默认:'SIGTERM') -
uid,数字,设置用户进程的 ID -
gid,数字,设置进程组的 ID
-
-
callback:回调函数,包含三个参数error,stdout和stderr。
返回最大的缓冲区,并等待进程结束,一次性返回缓冲区的内容。
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var workerProcess = child_process.exec('node support.js '+i, function (error, stdout, stderr) {
if (error) {
console.log(error.stack);
console.log('Error code: '+error.code);
console.log('Signal received: '+error.signal);
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
});
workerProcess.on('exit', function (code) {
console.log('子进程已退出,退出码 '+code);
});
}
spawn方法
child_process.spawn 使用指定的命令行参数创建新进程,语法格式如下:
child_process.spawn(command[, args][, options])
参数说明如下:
-
command: 将要运行的命令 -
args: Array 字符串参数数组 -
options-
cwd:String 子进程的当前工作目录 -
env:Object 环境变量键值对 -
stdio:Array|String 子进程的 stdio 配置 -
detached:Boolean 这个子进程将会变成进程组的领导 -
uid:Number 设置用户进程的 ID -
gid:Number 设置进程组的 ID
-
spawn方法返回流 (stdout & stderr),在进程返回大量数据时使用。进程一旦开始执行时 spawn() 就开始接收响应。
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var workerProcess = child_process.spawn('node', ['support.js', i]);
workerProcess.stdout.on('data', function (data) {
console.log('stdout: ' + data);
});
workerProcess.stderr.on('data', function (data) {
console.log('stderr: ' + data);
});
workerProcess.on('close', function (code) {
console.log('子进程已退出,退出码 '+code);
});
}
fork 方法
child_process.fork 是 spawn() 方法的特殊形式,用于创建进程,语法格式如下:
child_process.fork(modulePath[, args][, options])
-
modulePath: String,将要在子进程中运行的模块 -
args: Array 字符串参数数组 -
options:Object-
cwd:String 子进程的当前工作目录 -
env:Object 环境变量键值对 -
execPath:String 创建子进程的可执行文件 -
execArgv: Array 子进程的可执行文件的字符串参数数组(默认:process.execArgv) -
silent:Boolean 如果为true,子进程的stdin,stdout和stderr将会被关联至父进程,否则,它们将会从父进程中继承。(默认为:false) -
uid:Number 设置用户进程的 ID -
gid:Number 设置进程组的 ID
-
返回的对象除了拥有ChildProcess实例的所有方法,还有一个内建的通信信道。
const fs = require('fs');
const child_process = require('child_process');
for(var i=0; i<3; i++) {
var worker_process = child_process.fork("support.js", [i]);
worker_process.on('close', function (code) {
console.log('子进程已退出,退出码 ' + code);
});
}
多线程
Node.js V10.5.0 提供了 worker_threads,它比 child_process 或 cluster更轻量级。 与child_process 或 cluster 不同,worker_threads 可以共享内存,通过传输 ArrayBuffer 实例或共享 SharedArrayBuffer 实例来实现。
Node.js 保持了JavaScript在浏览器中单线程的特点。它的优势是没有线程间数据同步的性能消耗也不会出现死锁的情况。所以它是线程安全并且性能高效的。
单线程有它的弱点,无法充分利用多核CPU 资源,CPU 密集型计算可能会导致 I/O 阻塞,以及出现错误可能会导致应用崩溃。
为了解决单线程弱点:
浏览器端: HTML5 制定了 Web Worker 标准(Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行)。
Node端:采用了和 Web Worker相同的思路来解决单线程中大量计算问题 ,官方提供了 child_process 模块和 cluster 模块, cluster 底层是基于child_process实现。
开启现成的方法
使用 Worker 类
通过 Worker 类可以创建和管理工作线程。例如,可以创建一个新的线程,并传递一个 js 文件给该线程执行:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker('./my-worker.js');
// 主线程的逻辑
} else {
// 工作线程的逻辑
parentPort.postMessage('来自工作线程的问候');
}
使用线程池
const WorkerPool = require('workerpool').pool;
const pool = WorkerPool({ maxWorkers: 4 });
pool.exec(someTask).then(result => {
// 处理结果
});
使用案例
1、创建工作线程
首先,创建一个工作线程负责计算斐波那契数列。将以下代码保存为 fibonacciWorker.js 文件:
const { parentPort } = require('worker_threads');
function calculateFibonacci(n) {
if (n <= 1) return n;
return calculateFibonacci(n - 1) + calculateFibonacci(n - 2);
}
parentPort.on('message', (n) => {
const result = calculateFibonacci(n);
parentPort.postMessage(result);
});
2、与主线程交互
在主线程中,创建多个工作线程,并分配任务给它们。以下是主线程的代码,可以保存为 main.js:
const { Worker } = require('worker_threads');
const numThreads = 4; // 假设我们使用四个工作线程
for (let i = 0; i < numThreads; i++) {
const worker = new Worker('./fibonacciWorker.js');
worker.on('message', (result) => {
console.log(`线程 ${i} 返回的斐波那契结果:${result}`);
});
worker.postMessage(40); // 计算第40个斐波那契数
}