变量
变量命名规范需要遵守标识符命名规范
变量的定义
name = 10
python和java变量的差别

python和java变量存储结构的区别
- Java中的基本类型变量,存放的是值
- Java中的引用类型变量,一般存放在栈内存中,而值存放在堆内存中(使用new关键字)或者常量池中
- Python中的变量存放的是值的地址
- Python中的变量(任何变量)类似于Java中的引用类型(String、数组、ArrayList、类等)
常量
Python 本身并没有提供像 C 或 Java 中那样的 const 关键字来定义常量。
在 Python 中,所有的变量都是可以重新赋值的。因此,Python 并没有内建的常量类型。不过,Python 通过 命名约定 来模拟常量的概念,通常使用全大写字母来表示常量,表示这些变量不应该被修改。
PI = 3.14159
MAX_CONNECTIONS = 100
数据类型
| 类型 | 描述 | 说明 |
|---|---|---|
| 数字(Number) | 支持整数(int)、浮点数、(float)、复数(complex)、布尔(bool) | 整数(int),如:10、-10 |
| 浮点数(float) | 小数 | 如:13.14、-13.14 |
| 复数(complex) | 以j结尾表示复数 |
如:4+3j, |
| 布尔(bool) | True本质上是一个数字记作1,False记作0 | |
| 字符串(str) | 描述文本的一种数据类型 | 字符串(string)由任意数量的字符组成 |
| 列表(list) | 有序的可变序列 | Python中使用最频繁的数据类型,可有序记录一堆数据 |
| 元组(tuple) | 有序的不可变序列 | 可有序记录一堆不可变的Python数据集合 |
| 集合(set) | 无序不重复集合 | 可无序记录一堆不重复的Python数据集合 |
| 字典(dict) | 无序Key-Value集合 | 可无序记录一堆Key-Value型的Python数据集合 |
1、数字类型
int(整数)
整形,正负都可以,可以处理任意大小的整数
对于很大的数,例如10000000000,很难数清楚0的个数。Python允许在数字中间以_分隔,因此,写成10_000_000_000和10000000000是完全一样的
a = 10
b = -20
print(a)
float(浮点数)
浮点类型,也就是小数类型
a = 1.22
b = -2.33
print(a)
complex(复数)
复数(Complex),是 Python 的内置类型,直接书写即可。换句话说,Python 语言本身就支持复数,而不依赖于标准库或者第三方库
复数由实部(real)和虚部(imag)构成,在 Python 中,复数的虚部以j或者J作为后缀
c1 = 12 + 0.2j
print("c1Value: ", c1)
2、bool(布尔)
布尔类型,和java一样,但是首字母需要大写,python3的bool是int类型
a = True
b = False
print(a)
3、str(字符串)
python的String类型,也就是用单引号或双引号框起来的字符串
# 双引号
a = "abcdefg"
# 单引号
b = '1234567'
# 多行字符串
c = """你好呀
我是字符串多行的写法
使用三个双引号表示"""
print(c)
#根据索引截取字符串,格式a[i:j]
#i、j默认为0,表示截取字符串第i位到第j位不包括第j位
print(a[:2]) #ab
print(a[-3:-1]) #ef
print(a[2:]) #cdefg
#重复输出字符串
print(a * 2) #abcdefgabcdefg
#判断字符串a中是否存在给定字符串de
print('de' in a) #True
#判断字符串a中是否不存在给定字符串de
print('de' not in a) #False
#原始字符串,即忽略所有转义字符,按照实际字面量输出,r/R
print(r'\n') #\n
#将对象转化为供解释器读取的形式,即字符串化
print(repr(str))
模板字符串
方式一:占位符
| 格式符号 | 转化 |
|---|---|
%s |
将内容转换成字符串,放入占位位置 |
%d |
将内容转换成整数,放入占位位置 |
%f |
将内容转换成浮点型,放入占位位置 |
name = "lucy"
age = 18
msg = "我是%s,今年%s岁" % (name,age)
print(msg)
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
.n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:
%5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
%5.2f:表示将宽度控制为5,将小数点精度设置为2,小数点和小数部分也算入宽度计算。如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
方式二:format方法
name = "lucy"
age = 18
msg = "我是{},今年{}岁".format(name,age)
print(msg)
方式三:f-string
f其实就等价于format,只要你用过format,就会用这个。
这个是python3.6新增的特性。
name = "lucy"
age = 18
msg = f"我是{name},今年{age}岁"
print(msg)
花括号双写可以转义
times1 = 1000
times2 = 2000
print(f'文章中 {{ 符号 出现了 {times1} 次')
print(f'文章中 }} 符号 出现了 {times2} 次')
常用方法
capitalize() # 将字符串的第一个字符转换为大写
center(width, fillchar) # 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
count(str, beg= 0,end=len(string)) # 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
bytes.decode(encoding="utf-8", errors="strict") # Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。
encode(encoding='UTF-8',errors='strict') # 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace'
endswith('obj',beg=0, end=len(string)) # 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False.
expandtabs(tabsize=8) # 把字符串 string 中的tab符号转为空格,tab 符号默认的空格数是 8 。
find(str, beg=0, end=len(string)) # 检测str是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
index(str, beg=0, end=len(string)) # 跟find()方法一样,只不过如果str不在字符串中会报一个异常。
isalnum() # 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
isalpha() # 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False
isdigit() # 如果字符串只包含数字则返回 True 否则返回 False
islower() # 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
isnumeric() # 如果字符串中只包含数字字符,则返回 True,否则返回 False
isspace() # 如果字符串中只包含空白,则返回 True,否则返回 False.
istitle() # 如果字符串是标题化的(见 title())则返回 True,否则返回 False
isupper() # 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
join(seq) # 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
len(string) # 返回字符串长度
ljust(width[, fillchar]) # 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。
lower() # 转换字符串中所有大写字符为小写.
lstrip() # 截掉字符串左边的空格或指定字符。
maketrans() # 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
max(str) # 返回字符串 str 中最大的字母。
min(str) # 返回字符串 str 中最小的字母。
replace(old, new [, max]) # 将字符串中的 old替换成new后返回,如果 max 指定,则替换不超过 max 次。
rfind(str, beg=0,end=len(string)) # 类似于 find()函数,不过是从右边开始查找.
rindex(str, beg=0, end=len(string)) # 类似于 index(),不过是从右边开始.
rjust(width,[, fillchar]) # 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
rstrip() # 删除字符串末尾的空格或指定字符。
split(str="", num=string.count(str)) # 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串
splitlines([keepends]) # 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
startswith(substr, beg=0,end=len(string)) # 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。
strip([chars]) # 在字符串上执行 lstrip()和 rstrip()
swapcase() # 将字符串中大写转换为小写,小写转换为大写
title() # 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())
translate(table, deletechars="") # 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中
upper() # 转换字符串中的小写字母为大写
zfill (width) # 返回长度为 width 的字符串,原字符串右对齐,前面填充0
isdecimal() # 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。
string模块
import string
# 一些均为string的属性
ascii_letters #获取所有ascii码中字母字符的字符串(包含大写和小写)
ascii_uppercase #获取所有ascii码中的大写英文字母
ascii_lowercase #获取所有ascii码中的小写英文字母
digits #获取所有的10进制数字字符
octdigits #获取所有的8进制数字字符
hexdigits #获取所有16进制的数字字符
printable #获取所有可以打印的字符
whitespace #获取所有空白字符
punctuation #获取所有的标点符号
4、空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值
5、容器类型
除了List(列表)、Tuple(元组)、Dictionary(字典)、Set(集合)之外,String(字符串)也属于容器类型
1、list(列表)
列表,相当于java的ArrayList,可以嵌套,可以进行增删(可变),有序,自动扩容,使用[]表示
可以存储不同的数据类型
# 声明带有字面量的列表
names = ['tom','lucy','lily','jatlin']
# 声明带有变量的列表
names = [n1,n2,n3,n4]
# 声明空列表
names = []
names = list()
相关方法
#查看列表的元素个数
len(names)
#访问指定索引的元素
names[0]
#获取最后一个元素
names[-1]
#添加元素到列表最后
names.append('james')
#插入元素到指定索引位置
names.insert(1,'mary')
#删除末尾的元素,并得到这个元素
names.pop()
#删除指定索引的元素,并得到这个元素
names.pop(1)
#从前往后,删除第一个匹配的元素
names.remove('lucy')
#替换指定索引的元素
names[1] = 'jack'
#切片第二个到第四个,不包括第四个
names[1:4]
#判断是否包含某个元素
'tom' in names
#查看元素出现的次数
names.count('tom')
#查找元素
names.index('tom')
2、tuple(元组)
元组,和列表非常相似,但是不可以进行增删改(不可变),有序,只可以进行查询,使用()表示
a = ('lucy', 'tom', 'james')
print(a)
#只有一个元素也会加逗号,消除歧义
b = (1,)
print(b)
3、dict(字典)
字典,类似于java的HashMap,key-value形式,写法和json类似,无序(python3有序),可变,使用{}表示
一个字典中key是唯一的,如果出现多个key,那么会保存最后一次该key的value
students = {'tom':18,'lucy':22}
#新增元素
students['james'] = 25
#根据key获取value值,如果key不存在会报错
print(students['lucy'])
#判断key是否存在,返回boolean类型
isExist = 'lucy' in students
print(isExist)
#根据key获取value值,key不存在会返回None,或者自己指定的值
age = students.get('lily',99)
print(age)
#根据key删除元素,并获取该key对应的value
print(students.pop('tom'))
#获取键值对的个数
print(len(students))
#获取所有的 key
print(students.keys())
# 清空字典
students.clear()
遍历字典
a = {'name':'lucy','age':18,'grade':9}
# 通过遍历key,也可以写成 for key in a.keys
for key in a:
print(key,a[key])
# 遍历values
for value in a.values():
print(value)
# 遍历字典项,每一项是一个元组
for k,v in a.items():
print(k,v)
4、Set(集合)
集合,无序(python3有序),不可重复,基本功能是进行成员关系测试和删除重复元素
可以使用大括号{ } 或者set()函数创建集合。
注意:创建一个空集合必须用set()而不是{ },因为{ }是用来创建一个空字典
#创建方式一:通过一个列表来创建集合
names = set(['tom','lucy'])
#创建方式二:直接创建
names = {'lucy','mary'}
#创建空集合
names = set()
相关方法
#集合的修改,因为集合是无序的,所以集合不支持下标索引访问
#添加一个元素,如果添加已存在的元素,不会有效果
names.add('james')
#删除一个元素
names.remove('tom')
#从集合中随机抽取一个元素,同时集合本身被修改,元素被移除
names.pop()
#清空集合
names.clear()
#set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作
#交集
print(names1 & names2)
#并集
print(names1 | names2)
容器通用功能总览
| 功能 | 描述 |
|---|---|
| 通用for循环 | 遍历容器(字典是遍历key) |
max() |
容器内最大元素 |
min() |
容器内最小元素 |
len() |
容器元素个数 |
list() |
转换为列表 |
tuple() |
转换为元组 |
str() |
转换为字符串 |
set() |
转换为集合 |
sorted(序列, [reverse=True]) |
排序,reverse=True表示降序得到一个排好序的List(列表) |
python和java数据类型的对比
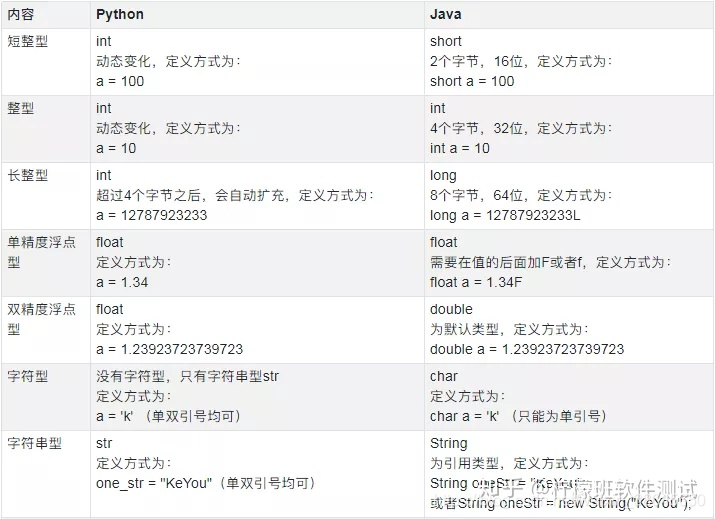
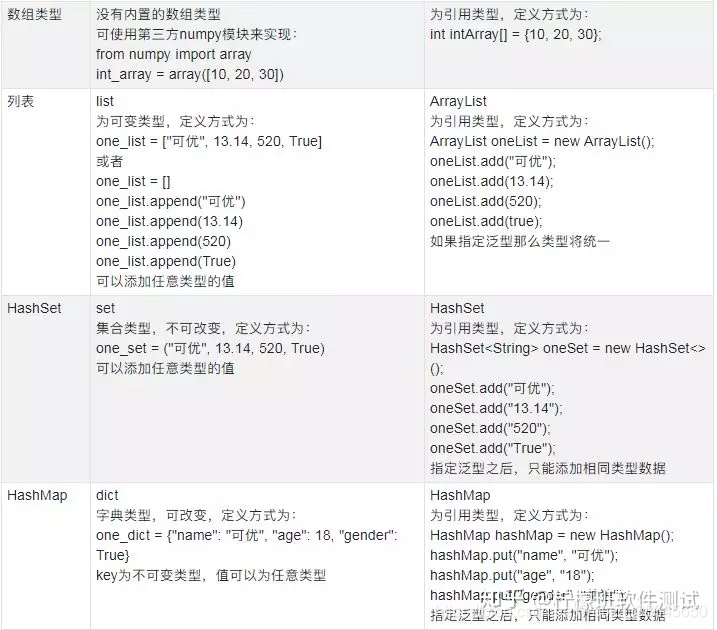
查看变量中数据的类型
注意:Python中变量没有具体的数据类型,数据类型取决与变量指向的数据的类型
a = {"lucy": 12, "tom": 18}
typeOfa = type(a)
print(typeOfA)
# <class 'dict'>
类型转换
基本类型的转换
int(a):将a转为int
float(a):将a转为float
str(a):将a转为String
bool(a):将a转为boolean,对于int,0为False,其他都是True,对于字符串,以及集合类型,只要有内容就是True,没有内容就是False
容器类型的转换
list(容器):将给定容器转换为列表
str(容器):将给定容器转换为字符串
tuple(容器):将给定容器转换为元组
set(容器):将给定容器转换为集合
运算符
算数运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
+ |
加 | 两个对象相加 a + b 输出结果 30 |
- |
减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
* |
乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
/ |
除 | b / a 输出结果 2(Python中的这种除法会带有余数) |
// |
取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
% |
取余 | 返回除法的余数 b % a 输出结果 0 |
** |
指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
赋值运算符
基本赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
= |
赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
=,将等号右边的值,赋值给左边的变量,和java一样,只是某些格式是java没有的
# 可以连续赋值
a = b = 12;
print(a)
# 多个变量同时分别赋值
a,b,c = 11,12,13
print(a)
复合赋值运算符
类似与java的+=、*=
| 运算符 | 描述 | 实例 |
|---|---|---|
+= |
加法赋值运算符 | c += a 等效于 c = c + a |
-= |
减法赋值运算符 | c -= a 等效于 c = c - a |
*= |
乘法赋值运算符 | c *= a 等效于 c = c * a |
/= |
除法赋值运算符 | c /= a 等效于 c = c / a |
%= |
取模赋值运算符 | c %= a 等效于 c = c % a |
**= |
幂赋值运算符 | c **= a 等效于 c = c ** a |
//= |
取整除赋值运算符 | c //= a 等效于 c = c // a |
比较运算符
和java一样,返回的都是boolean类型的数据
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 判断内容是否相等,满足为True,不满足为False | 如a=3,b=3,则(a == b) 为 True |
| != | 判断内容是否不相等,满足为True,不满足为False | 如a=1,b=3,则(a != b) 为 True |
| > | 判断运算符左侧内容是否大于右侧满足为True,不满足为False | 如a=7,b=3,则(a > b) 为 True |
| < | 判断运算符左侧内容是否小于右侧满足为True,不满足为False | 如a=3,b=7,则(a < b) 为 True |
| >= | 判断运算符左侧内容是否大于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a >= b) 为 True |
| <= | 判断运算符左侧内容是否小于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a <= b) 为 True |
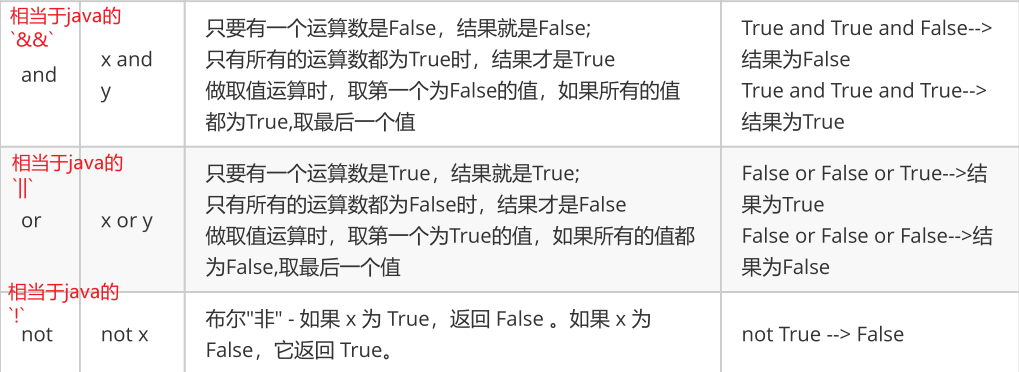
逻辑运算符
相比于java,没有|、&,在python中and、or都是短路的
进制
进制前面一般会有一个符号,这个符号表明了到底是多少进制。比如:
-
二进制前面的符号是
0b; -
八进制前面的符号是
0o; -
十六进制前面的符号是
0x; -
十进制前面一般没有符号。
二进制
a = 12
a_bin = bin(a) # 十进制转二进制
print(a_bin) # 0b1100
a = int(0b1100) # 二进制转十进制
print(a) # 12
八进制
a = 12
a_oct = oct(a) # 十进制转八进制
print(a_oct) # 0o14
a = int(0o14) # 八进制转十进制
print(a) # 12
十六进制
a = 12
a_hex = hex(a) # 十进制转十六进制
print(a_hex) # 0xc
a = int(0xc) # 十六进制转十进制
print(a) # 12
转换为字符串
a = 12
print(format(a, 'b')) # 1100 二进制
print(format(a, 'o')) # 14 八进制
print(format(a, 'x')) # c 十六进制
print(format(a, 'd')) # 12 十进制
字符集编码
字符集和编码的理解
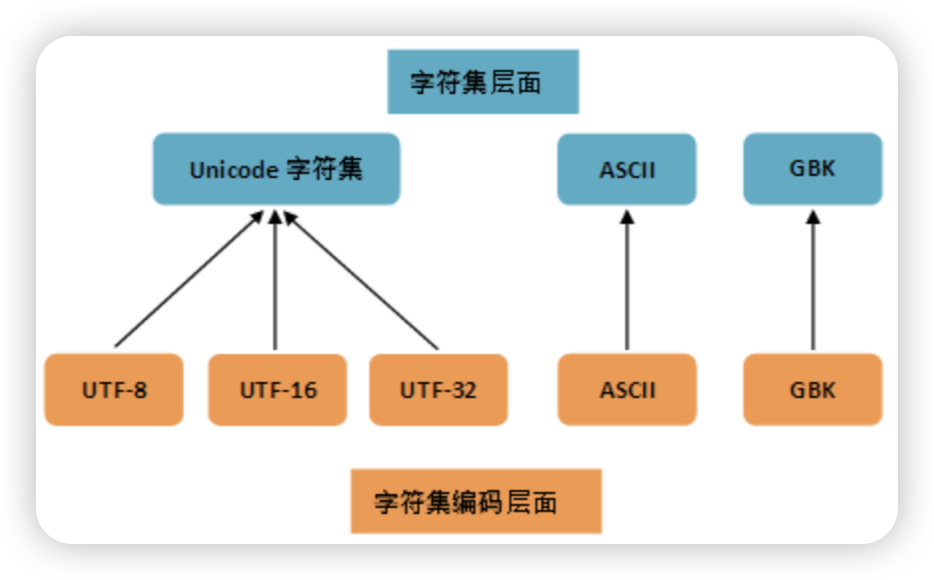
字符集(Character Set)
- 定义:字符的集合,定义了文本中可以使用的所有字符(如字母、数字、符号、汉字等)。
- 作用:规定哪些字符是合法的。
- 例子
- ASCII:包含 128 个字符(如
A-Z,a-z,0-9, 符号)。 - Unicode:包含 143,859 个字符(覆盖几乎所有语言的字符)。
- ASCII:包含 128 个字符(如
编码(Encoding)
- 定义:将字符集中的每个字符映射到二进制数字的规则。
- 作用:规定字符如何存储为二进制。
- 例子
- ASCII 编码:用 7 位二进制表示 ASCII 字符(如
A→01000001)。 - UTF-8 编码:用 1~4 字节表示 Unicode 字符(如
你→11100100 10111101 10100000)。
- ASCII 编码:用 7 位二进制表示 ASCII 字符(如
理解
最开始的计算机使用ASCII字符集,但是ASCII只包含了字母数字符号。
后面出现了Unicode 字符集,整理了世界上大部分的字符。
字符集,就是由码点和字符一一对应的。
码点:从 0 开始编号,每个字符都分配一个唯一的码点,完整的十六进制格式是 U+[XX]XXXX,具体可表示的范围为 U+0000 ~ U+10FFFF (所需要的空间最大为 3 个字节的空间),例如 U+0011 。这个范围可以容纳超过 100 万个字符,足够容纳目前全世界已创造的字符。
Unicode 本身只定义了字符与码点的映射关系,相当于定义了一套标准,而这套标准真正在计算机中落地时,则有多种编码格式。常见的有 3 种编码格式:UTF-8、UTF-16 和 UTF-32。UTF是英文 Unicode Transformation Format 的缩写,意思是 Unicode 字符转换为某种格式。
别看编码格式五花八门,本质上只是出于空间和时间的权衡,对同一套字符标准使用不同的编码算法而已。
例如,字符 A 的 Unicode 码点和编码如下:
- 图像(字符):
A - 码点:
U+0041 - UTF-8 编码:
0X41 - UTF-16 编码:
0X0041 - UTF-32 编码:
0X00000041
也就是说,当你根据 UTF-8、UTF-16 和 UTF-32 的编码规则进行解码后,你将得到的结果都是一样的:0x41。
Python中的编码处理
字符串和字节序列
字节序列
在 Python 中,以b开头的字节串来表示一个字节序列,即bytes
**注意:**这种以字符形式直接表示字节的方式只适用于 ASCII 编码的字符,即数字、字母、符号
sb = b'Hello,World'
print(sb[0]) # 72
编码
对于包含中文的字符,可以使用encode()方法按照指定的字符集编码规则进行编码,不传参数默认是utf-8
s = 'Hello,世界'
print(s.encode('utf-8')) # b'Hello,\xe4\xb8\x96\xe7\x95\x8c'
解码
对于字节序列,可以使用decode()方法按照指定的字符集编码规则进行解码,不传参数默认是utf-8
s = 'Hello,世界'
sb = s.encode('utf-8')
print(sb) # b'Hello,\xe4\xb8\x96\xe7\x95\x8c'
s = sb.decode('utf-8')
print(s) # Hello,世界
Unicode码点
ord():获取单个字符的Unicode码点
chr():或通过Unicode码点转化为字符。
注意:这两个方法操作的是 Unicode 字符集的码点,而上面的encode()和decode()方法是按照编码规则进行编解码。
cp_1 = ord('你')
cp_2 = ord('好')
print(cp_1) # 20320
print(cp_2) # 22909
c_1 = chr(cp_1)
c_2 = chr(cp_2)
print(c_1) # 你
print(c_2) # 好